Back in January 2025, multiple different security researchers published a total of 6 security vulnerabilities in rsync, some of which allow arbitrary code execution and file leaks, so naturally I was wondering whether/how my gokrazy/rsync implementation was affected. Did implementing my own (compatible, but minimal) rsync in Go, a modern and memory-safe programming language, really rule out entire classes of security vulnerabilities?
This deep dive article was in the making since January 2025, but was delayed because we uncovered more unpublished vulnerabilities in the process! The “Security Vulnerabilities” section now covers all 12 vulnerabilities from the January 2025 batch and the May 2026 batch.
If you are running (upstream, samba) rsync in production, upgrade to version 3.4.3 or newer.
If you are running gokrazy/rsync in production, upgrade to version v0.3.3 or newer.
Feel free to skip over the nitty-gritty security issue details and jump directly to:
- The verdict on whether using Go has helped.
- The verdict on whether a minimal re-implementation like gokrazy/rsync helps.
- My comparison with OpenBSD’s
openrsync(written in C). - Defense in depth mechanisms one can use on Linux.
- The conclusion.
Context: My own rsync
For context, I blogged about rsync, how I use it, and how it works back in June 2022. See also all posts tagged “rsync”.
The original motivation for writing my own rsync (back then only a server, today all directions are supported) was to provide the software packages of distri, my Linux distribution research project for fast package management, which I wanted to host on router7, my small home Linux+Go internet router, which in turn is built on gokrazy, my Go appliance platform.
I am still running multiple gokrazy/rsync servers for this original purpose, and also many others! Having rsync available as a primitive (that you can link into your Go programs!) is really nice.
Security Vulnerabilities
This article covers the following security vulnerabilities:
- CVE-2024-12084 to 12088 (original report)
- CVE-2024-12747 (discovered separately by Aleksei Gorban “loqpa”)
- CVE-2026-29518 (discovered by Damien Neil and myself! and independently by Nullx3D)
- CVE-2026-43617 to 43620
- CVE-2026-45232
The first batch of the vulnerabilities above was announced on the oss-security mailing list, but note that the original report has more detail compared to the oss-security summaries!
The later vulnerabilities were announced via GitHub Security Advisories on the rsync project.
January 2025 batch
CVE-2024-12084: Heap Buffer Overflow (9.8)
Summary:
- rsync performed insufficient validation: It read the (attacker-controlled)
checksum length from the network and compared the length against
MAX_DIGEST_LEN. - However, rsync’s data structures always declared a 16 byte buffer:
char sum2[SUM_LENGTH] - Hence, the bounds check was ineffective! An attacker could write out of bounds.
- This issue was introduced with commit
ae16850in September 2022, which added SHA256/SHA512 checksum support.
Click to expand the full description of the improper checksum length validation (quoting the Google Security report)
When the checksums are read by the daemon, two different checksums are read:
- A 32-bit Adler-CRC32 Checksum
- A digest of the file chunk. The digest algorithm is determined at the beginning of the protocol negotiation. The corresponding code can be seen below: sender.c:
s->sums = new_array(struct sum_buf, s->count); for (i = 0; i < s->count; i++) { s->sums[i].sum1 = read_int(f); read_buf(f, s->sums[i].sum2, s->s2length);Most importantly, note that
sum2field is filled withs->s2lengthbytes.sum2always has a size of 16: rsync.h#define SUM_LENGTH 16 // … struct sum_buf { OFF_T offset; /**< offset in file of this chunk */ int32 len; /**< length of chunk of file */ uint32 sum1; /**< simple checksum */ int32 chain; /**< next hash-table collision */ short flags; /**< flag bits */ char sum2[SUM_LENGTH]; /**< checksum */ };
s2lengthis an attacker-controlled value and can have a value up toMAX_DIGEST_LENbytes, as the next snipper shows:sum->s2length = protocol_version < 27 ? csum_length : (int)read_int(f); if (sum->s2length < 0 || sum->s2length > MAX_DIGEST_LEN) { rprintf(FERROR, "Invalid checksum length %d [%s]\n", sum->s2length, who_am_i()); exit_cleanup(RERR_PROTOCOL); }The problem here is that
MAX_DIGEST_LENcan be larger than 16 bytes, depending on the digest support the binary was compiled with:#define MD4_DIGEST_LEN 16 #define MD5_DIGEST_LEN 16 #if defined SHA512_DIGEST_LENGTH #define MAX_DIGEST_LEN SHA512_DIGEST_LENGTH #elif defined SHA256_DIGEST_LENGTH #define MAX_DIGEST_LEN SHA256_DIGEST_LENGTH #elif defined SHA_DIGEST_LENGTH #define MAX_DIGEST_LEN SHA_DIGEST_LENGTH #else #define MAX_DIGEST_LEN MD5_DIGEST_LEN /* 16 bytes */ #endif
SHA256support is common and sets theMAX_DIGEST_LENGTHvalue to 64. As a result, an attacker can write up to 48 bytes past thesum2buffer limit.
Upstream fix:
The upstream fix for
CVE-2024-12084
changes the sum2 field to a dynamically-allocated sum2_array field, which is
allocated with xfer_sum_len length, and fixes the bounds check to check
against the xfer_sum_len (checksum length for this transfer’s algorithm).
Can Go help prevent this?
Yes: Missing or incorrect bounds checks will not result in a heap buffer overflow in Go! Instead, attempting to write out of bounds will result in a panic because the Go runtime performs bounds checks.
How does gokrazy/rsync fare?
gokrazy/rsync also had insufficient validation! Our issue was different, though: It wasn’t size confusion, we just were not doing any validation of the sum header at all — oops!
We can confirm that the Go runtime’s bounds check triggers on an attempt to write out of bounds by changing the code like so and running the tests:
diff --git i/types.go w/types.go
index 5601697..899fcb8 100644
--- i/types.go
+++ w/types.go
@@ -59,7 +59,7 @@ func (sh *SumHead) WriteTo(c *rsyncwire.Conn) error {
var buf rsyncwire.Buffer
buf.WriteInt32(sh.ChecksumCount)
buf.WriteInt32(sh.BlockLength)
- buf.WriteInt32(sh.ChecksumLength)
+ buf.WriteInt32(512 /*sh.ChecksumLength*/)
buf.WriteInt32(sh.RemainderLength)
return c.WriteString(buf.String())
}
As expected, the Go runtime panics with the following message:
panic: runtime error: slice bounds out of range [:512] with length 16
goroutine 277 [running]:
github.com/gokrazy/rsync/rsyncd.(*sendTransfer).receiveSums(0xc0000d7b68)
/home/michael/go/src/github.com/gokrazy/rsync/rsyncd/sender.go:136 +0x339
github.com/gokrazy/rsync/rsyncd.(*sendTransfer).sendFiles(0xc0000d7b68, 0xc000120820)
/home/michael/go/src/github.com/gokrazy/rsync/rsyncd/sender.go:46 +0x134
github.com/gokrazy/rsync/rsyncd.(*Server).handleConnSender(0xc000476090, {{0x95ed9b, 0x7}, {0xc000426810, 0x2a}, {0x0, 0x0, 0x0}}, {0xa2a120, 0xc0000b2ba0}, ...)
/home/michael/go/src/github.com/gokrazy/rsync/rsyncd/rsyncd.go:397 +0x26a
github.com/gokrazy/rsync/rsyncd.(*Server).HandleConn(0xc000476090, {{0x95ed9b, 0x7}, {0xc000426810, 0x2a}, {0x0, 0x0, 0x0}}, {0xa2a120, 0xc0000b2ba0}, ...)
/home/michael/go/src/github.com/gokrazy/rsync/rsyncd/rsyncd.go:351 +0x37a
github.com/gokrazy/rsync/rsyncd.(*Server).HandleDaemonConn(0xc000476090, {0x94db80?, 0xc00018a040?}, {0x7fd15838b118, 0xc000428028}, {0xa2bd90, 0xc0002303c0})
/home/michael/go/src/github.com/gokrazy/rsync/rsyncd/rsyncd.go:307 +0xdbb
github.com/gokrazy/rsync/rsyncd.(*Server).Serve.func2()
/home/michael/go/src/github.com/gokrazy/rsync/rsyncd/rsyncd.go:450 +0xaf
created by github.com/gokrazy/rsync/rsyncd.(*Server).Serve in goroutine 260
/home/michael/go/src/github.com/gokrazy/rsync/rsyncd/rsyncd.go:448 +0xd2
Of course, crashing the entire server is not the best failure mode, so I added the missing bounds checking to turn the panic into an error.
CVE-2024-12085: Stack Info Leak Defeats ASLR (7.5)
Summary:
Because of the same lack of validation as in the previous CVE-2024-12084
vulnerability, an attacker could select a checksum algorithm with short
checksums (e.g. xxhash64 with 8 byte checksums), but then claim they were
sending longer checksums (e.g. 9 bytes), making the victim leak one byte of
uninitialized stack content in the response.
Leaking one byte of stack content may seem benign, but as the Google Security report puts it:
The first pair of vulnerabilities are a Heap Buffer Overflow and an Info Leak. When combined, they allow a client to execute arbitrary code on the machine a Rsync server is running on. The client only requires anonymous read-access to the server.
Click to expand the full description of the info leak (quoting the Google Security report)
The daemon matches checksums of chunks the client sent to the server against the local file contents in
hash_search(). Part of the function prologue is to allocate a buffer on the stack ofMAX_DIGEST_LENbytes:static void hash_search(int f, struct sum_struct *s, struct map_struct *buf, OFF_T len) { OFF_T offset, aligned_offset, end; int32 k, want_i, aligned_i, backup; char sum2[MAX_DIGEST_LEN];The daemon then iterates over the checksums the client sent and generates a digest for each of the chunks and compares them to the remote digest:
if (!done_csum2) { map = (schar *)map_ptr(buf, offset, l); get_checksum2((char *)map, l, sum2); done_csum2 = 1; } if (memcmp(sum2, s->sums[i].sum2, s->s2length) != 0) { false_alarms++; continue; }Notably, the number of bytes that are compared again are
s->s2lengthbytes. In this case, the comparison does not go out of bounds sinces->s2lengthcan be a maximum ofMAX_DIGEST_LEN.However, the local
sum2buffer, not to be confused with the attacker-controlleds->sums[i].sum2, is a buffer on the stack that is not cleared and thus contains uninitialized stack contents.A malicious client can send a (known)
xxhash64checksum for a given chunk of a file, which leads to the daemon writing 8 bytes to the stack buffersum2. The attacker can then sets->s2lengthto 9 bytes. The result of such a setup would be that the first 8 bytes match and an attacker-controlled 9th byte is compared with an unknown value of uninitialized stack data.An attacker can divide a file into 255 chunks and as a result leak one byte per file download. An attacker can incrementally repeat the process, either in the same connection or by resetting the connection.
As a result, they can leak
MAX_DIGEST_LEN - 8bytes of uninitialized stack data, which can contain pointers to Heap objects, Stack cookies, local variables and pointers to global variables and return pointers. With those pointers they can defeat ASLR.
Upstream fix:
There are two relevant upstream fixes:
- The “Some checksum buffer
fixes”
commit prevents this attack because the attacker-controlled
s->s2lengthcan no longer be larger than the transfer’s checksum length. - The “prevent information leak off the
stack”
commit initializes the
sum2memory to zero, thereby making any stack leak throughsum2impossible.
Can Go help prevent this?
Yes: By design, Go initializes all variables to the zero value. Go programmers do not need to remember to explicitly initialize variables.
How does gokrazy/rsync fare?
gokrazy/rsync is not affected by this vulnerability: Variables are always initialized in Go.
Additionally, selecting checksums other than MD4 was only introduced in protocol version 30 (gokrazy/rsync implements protocol version 27).
CVE-2024-12087: Path Traversal using Symlinks (7.5)
Description: (quoting the Google Security report)
When the syncing of symbolic links is enabled, either through the
-lor-a(--archive) flags, a malicious server can make the client write arbitrary files outside of the destination directory. A malicious server can send the client a file list such as:symlink -> /arbitrary/directory symlink/poc.txtSymbolic links, by default, can be absolute or contain characters such as
../../.In practice, the client validates the file list and when it sees the
symlink/poc.txtentry, it will look for a directory calledsymlink, otherwise it will error out. If the server sendssymlinkas [both, a directory and a symbolic link], [the client] will only keep the directory entry, thus the attack requires some more details to work.In
inc_recursemode, which the server can enable for the client, the server sends the client multiple file lists. The deduplication of the entries happens on a per-file-list basis. As a result, a malicious server can send a client multiple file lists, where:# file list 1: . ./symlink (directory) ./symlink/poc.txt (regular file) # file list 2: ./symlink -> /arbitrary/path (symlink)As a result, the
symlinkdirectory is created first andsymlink/poc.txtis considered a valid entry in the file list. Then, the attacker changes the type ofsymlinkto a symbolic link.When the server then instructs the client to create the
symlink/poc.txtfile, it will follow the symbolic link and thus files can be created outside of the destination directory.
Can Go help prevent this?
No. This vulnerability is caused by a logic error: when multiple file lists are used, the merged file list needs to be re-verified.
But see Defense in depth: Go’s os.Root
Upstream fix:
The upstream fix for CVE-2024-12087 adds the missing validation.
How does gokrazy/rsync fare?
gokrazy/rsync is not affected by this vulnerability: gokrazy/rsync does not
implement the incremental recursion mode (--inc-recursive).
The trade-off here is implementation complexity vs. resource usage: the incremental recursion mode allows working with the file set in a “windowed” way, as opposed to having to scan the entire file set before any transfer can begin. See also my How does rsync work? blog post.
CVE-2024-12088: Bypass for --safe-links (7.5)
Description: (quoting the Google Security report)
The
--safe-linksCLI flag makes the client validate any symbolic links it receives from the server. The desired behavior is that symbolic links target can only be 1) relative to the destination directory and 2) never point outside of the destination directory.The
unsafe_symlink()function is responsible for validating these symbolic links. The function calculates the traversal depth of a symbolic link target, relative to its position within the destination directory.As an example, the following symbolic link is considered unsafe:
{DESTINATION}/foo -> ../../As it points outside the destination directory. On the other hand, the following symbolic link is considered safe as it still points within the destination directory:
{DESTINATION}/foo -> a/b/c/d/e/f/../../This function can be bypassed as it does not consider if the destination of a symbolic link contains other symbolic links in the path. For example, take the following two symbolic links:
{DESTINATION}/a -> .{DESTINATION}/foo -> a/a/a/a/a/a/../../In this case, foo would actually point outside the destination directory. However, the
unsafe_symlink()function assumes thata/is a directory and that the symbolic link is safe.
Upstream fix:
The upstream fix for
CVE-2024-12088
makes unsafe_symlink() stricter by not allowing ../ anywhere within the
path, except at the very beginning.
Can Go help prevent this?
No. This vulnerability is caused by a logic error: the validation function was incorrect. We could have implemented that same bug.
But see Defense in depth: Go’s os.Root
How does gokrazy/rsync fare?
gokrazy/rsync is not vulnerable: The --safe-links feature is not yet
implemented in gokrazy/rsync.
CVE-2024-12086: Arbitrary File Leak (6.8)
Summary:
The rsync receiver (in client mode) did not sanitize file names provided by the rsync sender, or otherwise prevent opening files outside the destination tree. A malicious sender could instruct a receiver to compare checksums of arbitrary files outside the destination tree. By observing the receiver’s reaction to a provided one-byte checksum, a malicious sender can leak arbitrary files.
Click to expand the full description of the file leak (quoting the Google Security report)
When a client connects to a malicious server the server is able to leak the contents of an arbitrary file on the client’s machine. In
read_ndx_and_attrs()the client will readfnamecmptype as well as thexnamefrom the server if the server sets the appropriate flags. The flagsanitize_pathswill not be set for the client.if (iflags & ITEM_BASIS_TYPE_FOLLOWS) fnamecmp_type = read_byte(f_in); *type_ptr = fnamecmp_type; if (iflags & ITEM_XNAME_FOLLOWS) { if ((len = read_vstring(f_in, xname, MAXPATHLEN)) < 0) exit_cleanup(RERR_PROTOCOL); if (sanitize_paths) { /* not enabled when client receives */ sanitize_path(xname, xname, "", 0, SP_DEFAULT); len = strlen(buf); } } else { *buf = '\0'; len = -1; } *len_ptr = len;The caller (
recv_files()) then uses the server provided values to determine a file to compare the incoming data with.case FNAMECMP_FUZZY: if (file->dirname) { pathjoin(fnamecmpbuf, sizeof fnamecmpbuf, file->dirname, xname); fnamecmp = fnamecmpbuf; } else fnamecmp = xname; break; … fd1 = do_open(fnamecmp, O_RDONLY, 0);In
receive_data()the contents of the file specified byxnameare copied into the destination file. This can be achieved by the server sending a negative token.while ((i = recv_token(f_in, &data)) != 0) { ..snip.. if (i > 0) { ..snip.. } ..snip.. if (fd != -1 && map && write_file(fd, 0, offset, map, len) != (int)len)The server sends a checksum to compare. If they don’t match, a 0 is returned.
if (fd != -1 && memcmp(file_sum1, sender_file_sum, xfer_sum_len) != 0) return 0;When the return value is 0 the receiver will then send a
MSG_REDOto the generator. The generator will then write a message to the server.The server can use this as a signal to determine if the checksum they sent was correct. By starting off with a
blengthof 1 a malicious server is able to determine the contents of the target file byte by byte.
Upstream fix:
The upstream fix for CVE-2024-12086 prevents opening files outside the destination tree by verifying the sender-provided path.
Can Go help prevent this?
Yes, Go offers an API to prevent this, see Defense in depth: Go’s
os.Root.
How does gokrazy/rsync fare?
gokrazy/rsync is not vulnerable: the fuzzy matching feature was introduced with rsync protocol version 29, but gokrazy/rsync implements protocol version 27.
CVE-2024-12747: Symlink Race Condition (5.6)
Description: (quoting the Red Hat Security Advisory)
A flaw was found in rsync. This vulnerability arises from a race condition during rsync’s handling of symbolic links. Rsync’s default behavior when encountering symbolic links is to skip them. If an attacker replaced a regular file with a symbolic link at the right time, it was possible to bypass the default behavior and traverse symbolic links. Depending on the privileges of the rsync process, an attacker could leak sensitive information, potentially leading to privilege escalation.
Upstream fix:
The upstream fix for
CVE-2024-12747
changes open() calls in the rsync sender to use the O_NOFOLLOW option. The
paths are not expected to be symlinks at that point in the algorithm (symlinks
would be handled with readlink(2)
).
Can Go help prevent this?
Yes, Go offers an API to prevent this, see Defense in depth: Go’s
os.Root.
How does gokrazy/rsync fare?
gokrazy/rsync was vulnerable before commit
1b1fbf6,
which introduces the same O_NOFOLLOW mitigation that upstream rsync uses.
Click to expand the reproduction steps to trigger the
issue in gokrazy/rsync
To reproduce the issue, use the following steps:
-
Check out gokrazy/rsync v0.2.7:
git clone https://github.com/gokrazy/rsync cd rsync git checkout v0.2.7 -
Patch the code as follows to undo the fix and execute the attack:
diff --git i/internal/nofollow/nofollow_unix.go w/internal/nofollow/nofollow_unix.go --- i/internal/nofollow/nofollow_unix.go +++ w/internal/nofollow/nofollow_unix.go @@ -2,8 +2,6 @@ package nofollow -import "golang.org/x/sys/unix" - // Maybe resolves to unix.O_NOFOLLOW on unix systems, // 0 on other platforms. -const Maybe = unix.O_NOFOLLOW +const Maybe = 0 // unix.O_NOFOLLOW diff --git i/internal/sender/do.go w/internal/sender/do.go --- i/internal/sender/do.go +++ w/internal/sender/do.go @@ -2,6 +2,8 @@ package sender import ( "fmt" + "os" + "path/filepath" "sort" "github.com/gokrazy/rsync/internal/log" @@ -55,6 +57,15 @@ func (st *Transfer) Do(crd *rsyncwire.CountingReader, cwr *rsyncwire.CountingWri st.Logger.Printf("file list sent") } + // HACK: swap out the passwd file with a symlink to /etc/passwd + if err := os.Remove(filepath.Join(modPath, "passwd")); err != nil { + return nil, err + } + if err := os.Symlink("../passwd", filepath.Join(modPath, "passwd")); err != nil { + return nil, err + } + st.Logger.Printf("HACK: swapped passwd file for symlink") + // Sort the file list. The client sorts, so we need to sort, too (in the // same way!), otherwise our indices do not match what the client will // request.
Running the TestReceiverSymlinkTraversal test now shows that the server
traversed the symlink:
receiver_test.go:371: unexpected file contents: diff (-want +got):
bytes.Join({
- "benign",
+ "secret",
}, "")
A surprising discovery
When I shared a draft of this article with Damien Neil, member of the Go
Security Team and the author of the traversal-resistant os.Root
API, he pointed out:
I believe the gokrazy fix for CVE-2024-12747 is insufficient. You’re calling
os.OpenwithO_NOFOLLOW, butO_NOFOLLOWonly prevents symlink traversal in the last path component.This is probably still vulnerable to replacing an earlier path component so
os.Open("dir/passwd")can be redirected by symlinkingdirto/etc.
We reported this to the rsync security contact address in April 2025. In December 2025 I learned that someone else had also independently discovered and reported this issue.
Ultimately, this resulted in CVE-2026-29518, published on 2026-05-20.
May 2026 batch
CVE-2026-29518: Symlink Race Condition (7.0)
Description: (quoting the rsync 3.4.3 NEWS entry)
TOCTOU symlink race condition allowing local privilege escalation in daemon mode without chroot.
An rsync daemon configured with
use chroot = nois exposed to a time-of-check / time-of-use race on parent path components. A local attacker with write access to a module can replace a parent directory component with a symlink between the receiver’s check and its open(), redirecting reads (basis-file disclosure) and writes (file overwrite) outside the module. Under elevated daemon privilege this allows privilege escalation.Default
use chroot = yesis not exposed.Reach: local attacker on the daemon host, write access to a module path, daemon configured with
use chroot = no.
Upstream fix:
The upstream fix for
CVE-2026-29518
uses secure_relative_open(), which is similar to Go’s os.Root API.
Can Go help prevent this?
Yes, Go offers an API to prevent this, see Defense in depth: Go’s
os.Root.
How does gokrazy/rsync fare?
gokrazy/rsync was vulnerable until I switched the
sender
and the
receiver
to the traversal-resistant os.Root API.
CVE-2026-43618: Integer overflow leaks remote memory (8.1)
Description: (quoting the GitHub Security Advisory)
Description: The receiver’s compressed-token decoder accumulated a 32-bit signed counter without overflow checking. A malicious sender can trigger an overflow that, with careful manipulation, leaks process memory contents to the attacker – environment variables, passwords, heap and library pointers – significantly weakening ASLR and facilitating further exploitation.
Reach: authenticated daemon connection with compression enabled (the default for protocols >= 30 when both peers advertise it). Disabling compression on the daemon (“refuse options = compress” in rsyncd.conf) is the available workaround.
Upstream fix:
The upstream fix for CVE-2026-43618 introduces the missing checks.
How does gokrazy/rsync fare?
gokrazy/rsync is not vulnerable because it does not implement compression. See gokrazy/rsync issue #35 for details on why compression support sounds simple, but is non-trivial.
CVE-2026-43620: DOS after Out-of-bounds read (6.5)
Description: (quoting the GitHub Security Advisory)
The 2025 fix that added a
parent_ndx<0guard insend_files()was not applied to the visually-identical block inrecv_files(). A malicious rsync server can drive any connecting client into a deterministicSIGSEGVby settingCF_INC_RECURSEin the compatibility flags, sending a flist whose first sorted entry is not a leading “.” directory (which causesrecv_file_list()to setparent_ndx = -1), then sending a transfer record withndx=0and a non-ITEM_TRANSFERiflag word. The receiver readsdir_flist->files[-1]and dereferences the result. On glibc x86-64 the dereferenced pointer is mmap chunk metadata that lands at an unmapped address, hence a cleanSEGV_MAPERR; non-glibc allocators have not been audited.Reach: any rsync client doing a normal pull from an attacker-controlled URL. Works for both rsync:// URLs and remote-shell pulls.
inc_recurseis the protocol-30+ default; no special options are required on the victim.Workaround:
--no-inc-recursiveon the client.
Upstream fix:
The upstream fix for
CVE-2026-43620
adds the parent_ndx<0 guard to recv_files() as well.
How does gokrazy/rsync fare?
Just like for CVE-2024-12087, gokrazy/rsync is not affected
by this vulnerability: gokrazy/rsync does not implement the incremental
recursion mode (--inc-recursive).
CVE-2026-43619: More symlink races (6.3)
Description: (quoting the GitHub Security Advisory)
Description: Earlier fixes for symlink races on the receiver’s open() call (CVE-2026-29518) missed the same race class on every other path-based system call: chmod, lchown, utimes, rename, unlink, mkdir, symlink, mknod, link, rmdir, lstat. On rsync daemons with “use chroot = no” a local attacker with filesystem access on the daemon host can swap a symlink into a parent directory component between the receiver’s check and one of these syscalls, redirecting it outside the exported module. The fix routes each affected path-based syscall through a parent dirfd opened under RESOLVE_BENEATH-equivalent kernel-enforced confinement (openat2 on Linux 5.6+, O_RESOLVE_BENEATH on FreeBSD 13+ and macOS 15+, per-component O_NOFOLLOW walk elsewhere). Default “use chroot = yes” is not exposed.
Reach: local attacker on the daemon host, write access to a module path, daemon configured with use chroot = no.
Upstream fix:
The upstream fix for
CVE-2026-43619
uses the *at family of syscalls, just like Go’s os.Root.
Can Go help prevent this?
Yes, Go offers an API to prevent this, see Defense in depth: Go’s
os.Root.
How does gokrazy/rsync fare?
gokrazy/rsync is not affected, because it uses Go’s os.Root API throughout.
CVE-2026-43617: Hostname/ACL bypass (4.8)
Description: (quoting the GitHub Security Advisory)
On an rsync daemon configured with the global
daemon chroot = /Xrsyncd.conf setting, the reverse-DNS lookup of the connecting client was performed after the daemon had chrooted into/X. If/Xdid not contain the files glibc needs for resolution (/etc/resolv.conf,/etc/nsswitch.conf,/etc/hosts, NSS service modules), the lookup failed and the connecting hostname was set to “UNKNOWN”. Hostname-based deny rules (“hosts deny = *.evil.example”) therefore could not match, and an attacker controlling their PTR record could connect from a hostname the administrator had intended to deny. IP-based ACLs are unaffected. The per-moduleuse chrootsetting is unrelated to this issue.Reach: rsync daemon configured with
daemon chroot = /XAND hostname-based ACLs AND/Xdoes not include the libc resolver fixtures.
Upstream fix:
The upstream fix for CVE-2026-43617 moves the DNS lookup to an earlier point in the protocol.
How does gokrazy/rsync fare?
gokrazy/rsync is not vulnerable because we only implement IP-based allow/deny lists, not hostname-based allow/deny lists.
CVE-2026-45232: stack out-of-bounds write (3.1)
Description: (quoting the GitHub Security Advisory)
The rsync client’s HTTP
CONNECTproxy support contains an off-by-one out-of-bounds stack write inestablish_proxy_connection()(socket.c). After issuing theCONNECTrequest, rsync reads the proxy’s first response line one byte at a time into a 1024-byte stack buffer with the boundcp < &buffer[sizeof buffer - 1], so the loop only ever writesbuffer[0..sizeof-2]. If the proxy (or a man-in-the-middle in front of it) returns 1023+ bytes on the first response line without a'\n'terminator, the loop exits withcp == &buffer[sizeof buffer - 1]— a slot the loop never wrote, so*cpholds stale stack bytes left there by the earliersnprintf()that formatted the outgoingCONNECTrequest. The post-loop code then does:if (*cp != '\n') /* (*cp is uninitialised stack data) */ cp++; /* cp now &buffer[sizeof]: one past end */ *cp-- = '\0'; /* one-byte OOB write on the stack */The
'\0'lands one byte past the end of the on-stackbuffer[1024], corrupting whatever lives in the adjacent stack slot. AddressSanitizer reportsstack-buffer-overflowatsocket.c:95in theestablish_proxy_connectionframe.
Upstream fix:
The upstream fix for CVE-2026-45232 validates the attacker-supplied data.
How does gokrazy/rsync fare?
gokrazy/rsync does not implement such proxy support, so it is not vulnerable.
Go verdict
Let’s summarize how Go fares:
- The Go runtime’s bounds checks turn more serious security issues into a panic.
- A panic is still a denial-of-service risk, but that’s much preferable.
- Go initializes memory to zero, making info leaks like CVE-2024-12085 impossible.
- Go’s
os.RootAPI prevents most of the remaining vulnerabilities. - Only one out of twelve vulnerabilities (CVE-2026-43617) is a proper bug in the application logic that using Go could not have prevented.
| CVE number | Cause | Risk (C) | Does Go help? |
|---|---|---|---|
| 2024-12084 | insufficient validation | Heap Buffer Overflow | ✅ bounds check (panics!) |
| 2024-12085 | insufficient validation | Info Leak | ✅ zero init |
| 2024-12086 | missing validation | Arbitrary File Leak | ✅ os.Root |
| 2024-12087 | insufficient validation | Write Arbitrary Files | ✅ os.Root |
| 2024-12088 | insufficient validation | Create Arbitrary Symlinks | ✅ os.Root |
| 2024-12747 | TOCTOU | Leak Privileged Files | ✅ os.Root |
| 2026-29518 | TOCTOU | Leak Privileged Files | ✅ os.Root |
| 2026-43617 | missing validation | Deny List Ineffective | ❌ logic bug |
| 2026-43618 | insufficient validation | Info Leak | ✅ bounds check (panics!) |
| 2026-43619 | TOCTOU | Leak Privileged Files | ✅ os.Root |
| 2026-43620 | insufficient validation | crash (DOS) | ✅ bounds check (panics!) |
| 2026-45232 | missing validation | Memory Write | ✅ bounds check (panics!) |
gokrazy/rsync verdict
Aside from being written in Go, another key difference between gokrazy/rsync and the official upstream rsync is that the gokrazy implementation is minimal:
- gokrazy/rsync is unaffected by many vulnerabilities because it does not
implement the feature in question, for example
--inc-recursive. - Like all other wire protocol-compatible rsync implementations, gokrazy/rsync targets protocol version 27, because later protocol versions introduce significant complexity.
- In some cases, features that would be good to implement come with significant blockers, e.g. compression is tricky, see gokrazy/rsync issue #35 for details.
Let’s have a look at whether gokrazy/rsync was affected by each CVE at the time of publishing:
| CVE number | Cause | gokrazy/rsync impl? | gokrazy/rsync affected? |
|---|---|---|---|
| 2024-12084 | insufficient validation | yes | ⚠️ panic |
| 2024-12085 | insufficient validation | no (proto 30) | ✅ not vuln |
| 2024-12086 | missing validation | no (proto 29) | ✅ not vuln |
| 2024-12087 | insufficient validation | no (inc-rec) |
✅ not vuln |
| 2024-12088 | insufficient validation | no (safe-links) |
✅ not vuln |
| 2024-12747 | TOCTOU | yes | ❌ vuln |
| 2026-29518 | TOCTOU | yes | ⚠️ patched |
| 2026-43617 | missing validation | no (host deny lists) | ✅ not vuln |
| 2026-43618 | insufficient validation | no (compression) | ✅ not vuln |
| 2026-43619 | TOCTOU | yes | ⚠️ patched |
| 2026-43620 | insufficient validation | no (inc-rec) |
✅ not vuln |
| 2026-45232 | missing validation | no (proxy) | ✅ not vuln |
To be clear: all known vulnerabilities are fixed in gokrazy/rsync! The table above documents what the state was at the time when each CVE was published. In other words:
When the January 2025 vulnerabilities were published, gokrazy/rsync panicked
(CVE-2024-12084) and was vulnerable to a TOCTOU race (CVE-2024-12747). In the
process of fixing the TOCTOU issue, we discovered CVE-2026-29518, which was
fixed in gokrazy/rsync before the CVE was published. CVE-2026-43619 was
discovered even later, but was also already fixed in gokrazy/rsync with the same
fix: using Go’s os.Root everywhere.
Imprecise terminology
As I was reading the vulnerability reports, I noticed that the reports were slightly misleading by their choice of words: most reports just spoke of “server” and “client”. However, in an rsync transfer, both sides, the rsync client and the rsync server can assume either role: sender (upload files) or receiver (download files)!
Some setups come with further restrictions that make certain attacks harder or impossible to pull off. For example, when running in daemon mode, file system access can be restricted to the pre-configured module paths (but not in command mode!).
Here is a diagram to give you an overview of the 4 different setups and role/protocol layering:
 rsync --daemon (2) rsync -e ssh; rsync://server/module/dir (3) rsync server:/some/path (4) rsync /src")
In the context of our vulnerability reports, I would say that the Arbitrary File Leak vulnerability (CVE-2024-12086)’s original title “Server leaks arbitrary client files” can easily be misunderstood.
Instead, I would say: The rsync receiver will leak arbitrary files to a malicious sender.
I have verified that a malicious client sender can make an unpatched remote
rsync open files outside the destination tree (e.g. the /etc/shadow system
password database) when running in command mode, for example over SSH. (But,
when running in daemon mode, the server enables additional path sanitization,
which prevents this attack.)
Similarly, the Symlink Path Traversal vulnerability (CVE-2024-12087) speaks about a “malicious server”, but again, it should be “malicious sender”, which can be either the client or the server.
Comparison with OpenBSD’s openrsync (C)
The OpenBSD project is known for its security focus, so how does openrsync compare?
openrsync is not affected by the Heap Buffer Overflow (CVE-2024-12084) and Stack Info Leak (CVE-2024-12085) vulnerabilities because it validates the checksum length and only supports one checksum size/algorithm (MD4).
openrsync is not affected by CVE-2024-12086, CVE-2024-12087 and CVE-2024-12088
because it does not implement the relevant features (like gokrazy/rsync). Even
if it was vulnerable, openrsync’s defense-in-depth measures like using
OpenBSD’s unveil(2) and
pledge(2) to restrict file system access
would have prevented successful exploitation — at least when running on OpenBSD.
openrsync is not affected by CVE-2024-12747 because it used O_NOFOLLOW from
the very moment they implemented symlink
support. But,
because O_NOFOLLOW is not a sufficient fix for this issue, openrsync is
affected by CVE-2026-29518!
The above covers the January 2025 batch of vulnerabilities; the May 2026 batch is similar in that most features just are not implemented.
Overall, I say: Well done, Kristaps and contributors! By diligently implementing validation, restricting the attack surface and employing defense-in-depth measures, openrsync manages to not be affected by almost all of the reported vulnerabilities.
Defense in depth
Which APIs and environments can we use on Linux for defense-in-depth measures?
I’ll go through the ones gokrazy/rsync supports, ordered by traditional to
modern.
Linux mount namespaces
Within a few weeks after starting the gokrazy/rsync project, I added support
for dropping privileges and using mount/pid namespaces on
Linux
to restrict the file system objects that my rsync server could work with.
This approach works very well to mitigate path traversal attacks, but requires
privileges, meaning we need to run as root or in a Linux user
namespace
(if enabled on your distribution / system).
That limitation makes mount namespaces well-suited for server setups, but usually unavailable for interactive one-off transfers that are typically running under a human’s user account.
systemd hardening
In the same commit that introduced Linux mount/pid namespace support, I also included a systemd service file that restricted file system access to home directories and encouraged folks in the README to further restrict file system access, depending on what their use-case allows.
These file system restrictions, if set up correctly, mitigate the File Leak (CVE-2024-12086) and Path Traversal (CVE-2024-12087) vulnerabilities.
The Symlink Race Condition (CVE-2024-12747) relies on privilege escalation through the rsync process, but thanks to the DynamicUser feature, our process has fewer privileges than other users.
Similarly to mount namespaces, these measures are great for server setups, but too cumbersome to set up for interactive one-off usages.
Linux Landlock
I stumbled upon Justine’s blog post Porting OpenBSD pledge() to Linux
(2022) and was reminded that Linux offers
the Landlock API for
unprivileged, per-process access control, similar to OpenBSD’s
unveil(2) system call, which openrsync
uses. The basic idea is that once your program knows the directory it works
with, it makes a call like unveil("/home/michael/backups", "rw"); and no
longer has access to other file system locations.
I had previously heard of Landlock at a Go Meetup, so I knew there was Go support for Landlock. Back in 2022, I enabled Landlock support in the gokrazy kernel images.
So I gave it a shot in March 2025 and implemented Landlock support to restrict file system access. It took me a few hours, which seems a little longer than one might expect at first. Making Landlock work (and/or skipping it) in our test environment ran into a couple of road blocks: Our tests had defined many functions that get run in the same process, but when repeatedly adding rulesets, we would exceed the limit of 16 (!) policy layers per process.
Once I had it set up just right, it is a beautiful solution. Now we can restrict
rsync transfers to their sources (read-only) or destination directories
(read-write), even for unprivileged invocations of gokrazy/rsync! 🎉
The downside to Landlock is that Landlock operates at the process level. This
means that Landlock policies must include the files that your program needs,
e.g. gokrazy/rsync needs to be able to read /etc/passwd for user id lookup,
so if the attacker is after the /etc/passwd file, Landlock does not help.
Go’s os.Root
In February 2025, the Go 1.24 release introduced the
os.Root API, which is resistant against path
traversal, see The Go Blog: Traversal-resistant file
APIs (by Damien Neil, March 2025). This API allows
more fine-grained control (per file system operation) compared to Landlock.
Go 1.25 (released in August 2025) added more methods to os.Root, making it a
convenient choice for most file system usage.
I have converted all of gokrazy/rsync’s file system usage to use os.Root,
which is a great fit: users configure input/output directories, but the
filenames received over the network are untrusted. That’s exactly what os.Root
was designed for!
When I first looked into using os.Root, I thought that some system calls could
inherently not be made with this API, like for example mknod(2)
to create device node files. Damien explained:
It won’t support mknod, though.
However, you should be able to use it to enable a safe mknod:
- os.Root.OpenFile the parent directory of the target,
- File.Fd to get the file descriptor for that directory,
- https://pkg.go.dev/golang.org/x/sys/unix#Mknodat to create the file.
If you’re curious how that looks in practice, check out gokrazy/rsync’s usage
in internal/receiver/generatormknod_linux.go, line
15-29.
Another stumbling block was when I realized that unlike with mknodat(2)
, Linux only implements bind(2)
, but no bindat (as of Linux 7.0)!
Luckily, Lennart Poettering pointed
out that there’s a trick
to skip path resolution without bindat:
you can probably bind to
/proc/self/<fd>/foobarin the meantime…
And indeed, this works! Path resolution is skipped because we only specify a
basename (last component of a path) after the known-safe /proc/self/<fd>, not
a path (see line
49-56).
With these two tips, gokrazy/rsync v0.3.1 and newer are fully using os.Root,
meaning all file system access is traversal-safe! 🥳
Conclusion
Lacking validation causes vulnerabilities
It is interesting to note that aside from the TOCTOU vulnerabilities (CVE-2024-12747, CVE-2026-29518 and CVE-2026-43619), all other vulnerabilities were caused by missing or incorrect input validation. In three cases, there was just no validation to begin with. In another case (CVE-2024-12088), the subject matter of file system path resolution is tricky enough that the existing validation did not cover all edge cases.
As the Go verdict section explains in more detail, the most
valuable structural fixes are to provide bounds checking (= always-on
validation) and safe-by-default APIs like Go’s os.Root.
Too much complexity
A few of the vulnerabilities came from evolution of the rsync protocol: The code used to correctly perform sufficient validation, but then new features were added. For example, when checksum algorithm negotiation was added (protocol version 30), the validation was not correctly updated. When incremental recursion was added (also protocol version 30), the validation that made sense for individual file lists was not updated for the new processing approach of merging incremental file lists.
Avoiding complexity avoids vulnerabilities! Both gokrazy/rsync and also openrsync were not vulnerable to 8 out of the 12 security vulnerabilities simply because they do not implement the feature with the vulnerability.
Of course, these features were added to rsync because they were valuable to someone at some point, and of course I am not saying that we should just… not develop software any further, ever.
But, I consider it ideal to use an implementation whose complexity is appropriate for and proportional to the complexity of the use-case. In other words: for simple use-cases, reach for a simple implementation. Only reach for the fully-featured implementation where needed.

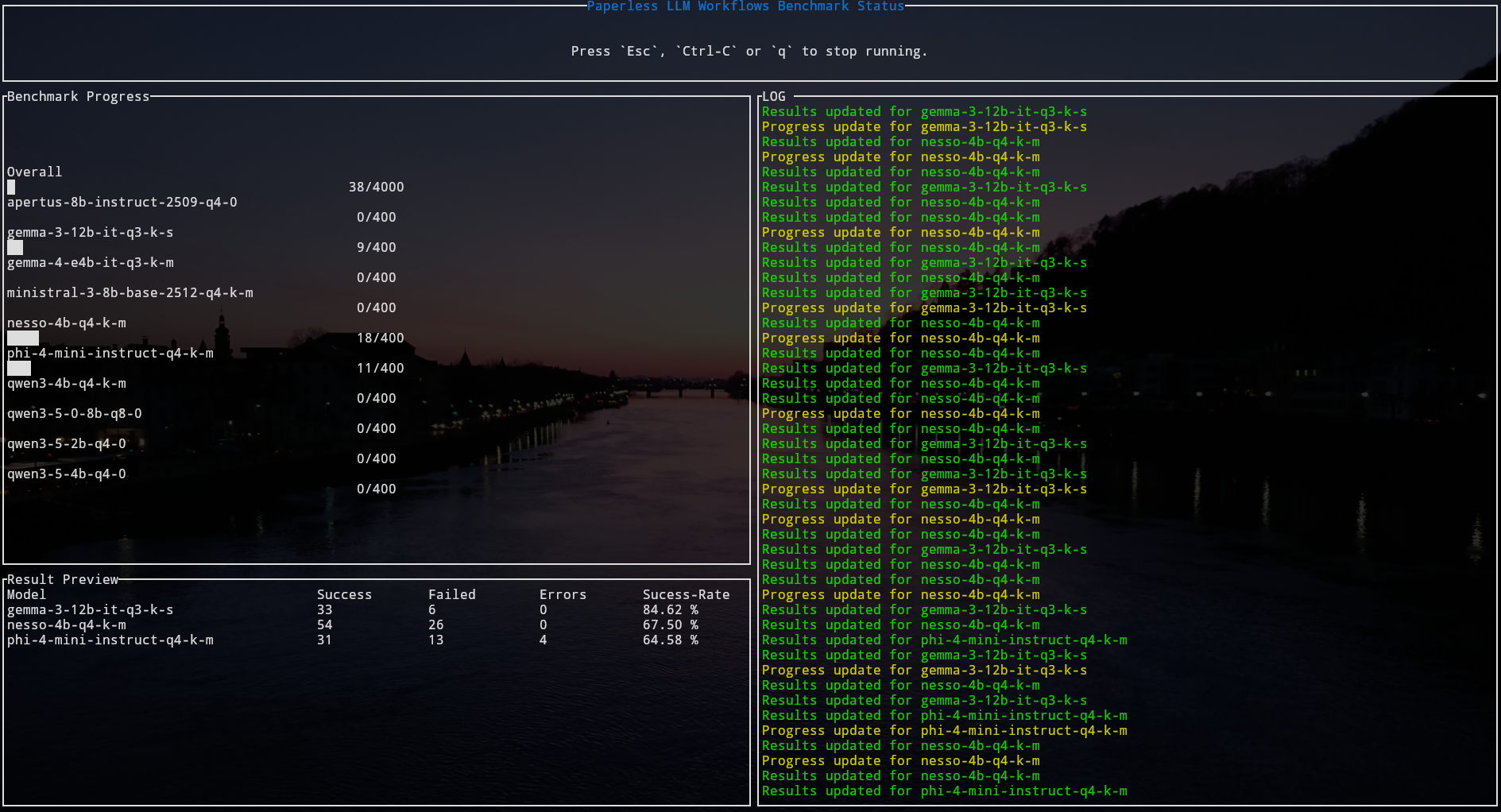
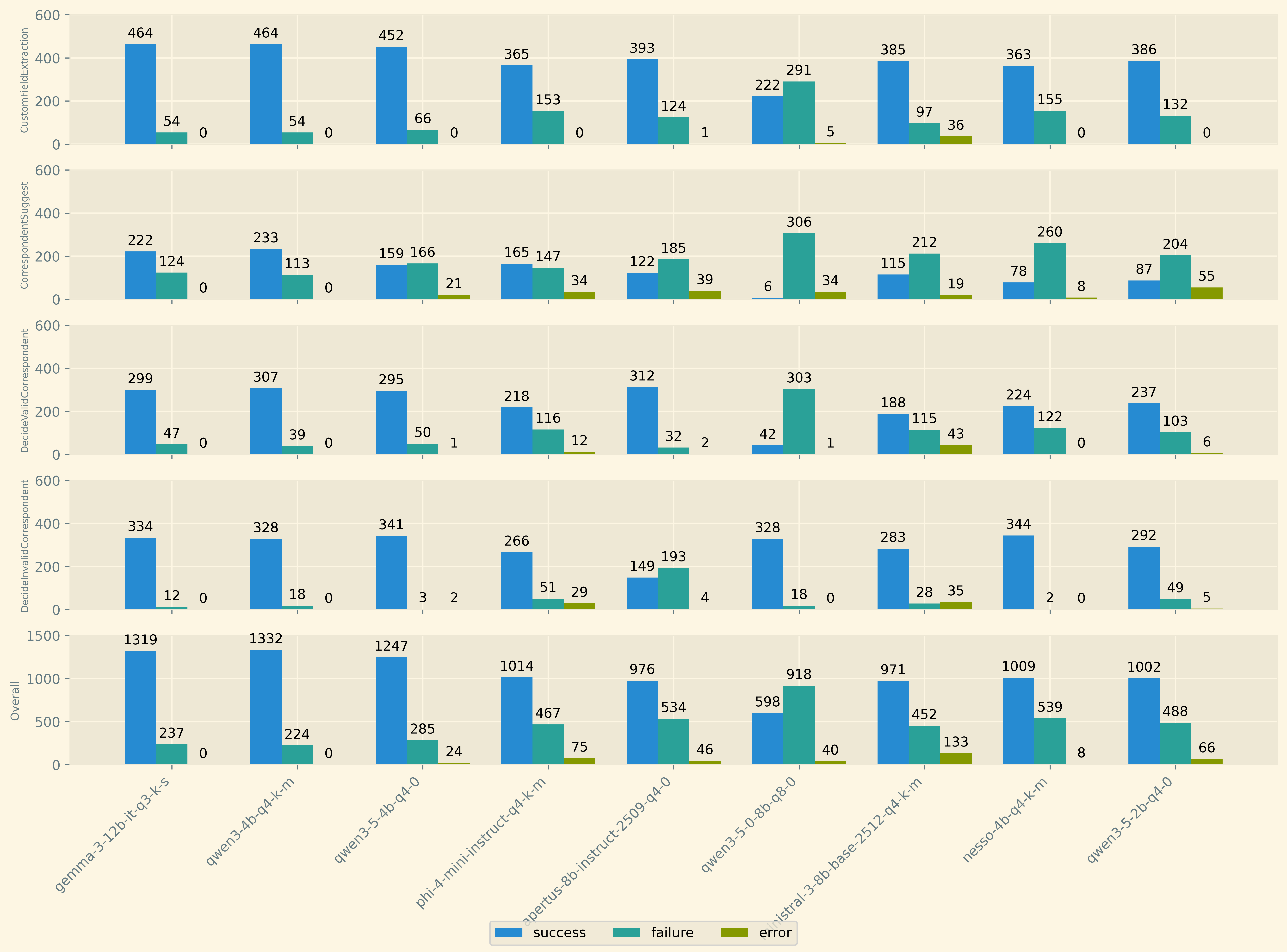








 output line highlights the whole line")


")

")








 vs. MacBook Pro (right)")





")
")
")